SSAS provides Process Incremental as one of the processing options for cubes, measure groups and partitions. It is important to understand how Process Incremental works because it differs significantly from the seemingly equivalent Process Update for dimensions.
Process Incremental is extremely useful to process facts having journal entries. In a journal fact, updates to existing fact records are balanced by a corresponding negative or positive journal entry. In Process Incremental mode, a SQL query has to be provided that could identify the records inserted into the fact journal since last cube process.
Screen Capture 1 – Process Incremental
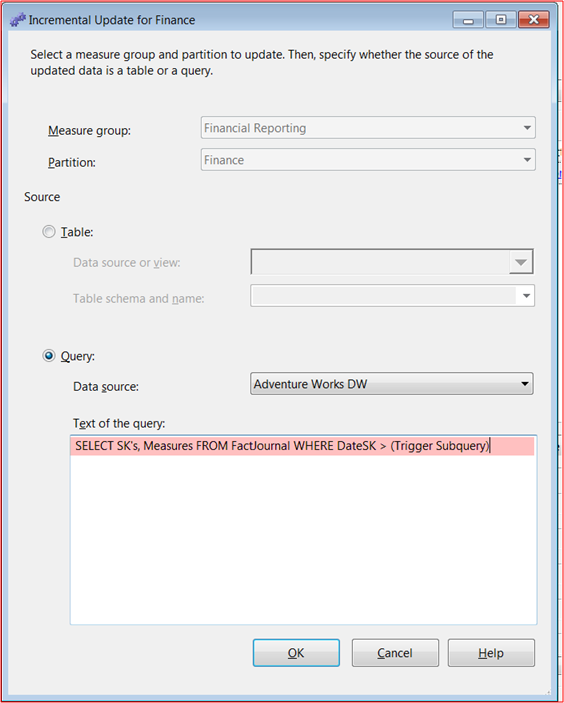
Screen Capture 2 – Process Incremental For Journal Fact
Process Incremental mode is also useful if the Data Warehouse has staging tables that contain the delta fact records for a specific run. In that case the SQL would be straight fetch from the delta fact table.

Screen Capture 3 – Process Incremental for Delta Facts
In fact, Process Incremental mode only adds fact records to cubes, measure groups and partitions. It cannot detect an update or delete. It is unlikely that Process Incremental mode would be used on Snapshot fact tables. In a Snapshot fact, records could be updated in place or deleted and replaced by a new fact record. If Process Incremental mode is used in such a scenario, it would introduce duplicate fact records in the partition.
Process Update, on the other hand for Dimensions could detect inserts, updates and deletes. I would say Process Incremental mode for cubes, measure groups and partitions is similar to Process Add of Dimensions and significantly different to Process Update.

Hi Austin,
I have a question for you.I have added a new attribute to a dimension table of an existing cube.Is there a way to avoid full processing of the cube and have the attribute value for the new records coming up?
Navneeth, adding a new attribute is a structural change for the cube. So you will have to reprocess.
I have gone through all the comments. So is it correct to use “Process Full” as best practice for Cube processing?
Subhodip, I would suggest Process Data the partition followed by Process Index https://bennyaustin.wordpress.com/2013/08/19/processcube/
Excellent article. Question about FULL versus INCREMENTAL. I have noticed that when performing a full process (as opposed to incremental), the performance for returning data from the cube is very slow afterward until I have returned data a couple of times (via a report for example). However, I do not see this same sort of behavior after incremental processing. Is this due to some sort of cache being cleared after a full process?
Scott, you are right. Cube processing will clear the cache. You could warm the cache by using mdx cache queries in your ETL http://richardlees.blogspot.com.au/2010/12/warming-olap-cache.html
So What I understand is,
For Process Increment if your load each time brings new records and has no connection with previous load (Specially for FACT) which could identify by query
AND
Your Dimension are only ADDING then
You can Use for FACT –> Process Increment(Specify By Query For New Records)
And For Dimensions –> Process Add (Specify By Query For New Records)
For Example Each Time When my Load Runs I gave them LOAD_ID and which is unique in FACT and Dimension and if I catch that recent LOAD_ID I will be all set?
How that sounds?
Syed, that’s right
Dear all. Thanks for your input. I have a datawarehouse which i am updating daily. I then process the olap cubes after the etl process, so in actual fact am processing a full update. If i flag the records in the data warehouse after the olap process as updated and then process incremental the next day, having only the unflagged records , will this increment the data in the cube?
Patrick, your method will work if your fact table is journal type fact where existing records are never updated or deleted and instead updates/ deletes are introduced as new journal entries. However if your fact table is a snapshot type fact then your method will introduce duplicates.
It is good to know that query specification is mandatory in case of Process Incremental unlike in the case for ProcessAdd for dimensions. ProcessAdd comes with an optional query for specifying the delta data, which is much faster than just reading the entire table data and then letting SSAS decide what the new records are.
I think this optional query specification for ProcessAdd for dimensions via XMLA could have been made mandatory
I have an situation where my existing records are getting updated. Lets say the sold amount of XXX item was 100$ and record has been processed into cube. Now the value got changed to 200$. I will use process incremental but how to remove the older value from the cube before doing process incremental?
Rakesh, for the scenario you mentioned Process Incremental is not the right processing option. Unless the underlying fact table can generate journal type entries, Process Incremental option is not advisable. For instance when the value changes from $100 to $150, instead of updating existing record if a new journal entry is created for $50 then Process Incremental would work.
I agree with you.
But i cannot create an extra entry for the sale price change. So what is the recommended way to handle this when we cannot use Process Incremental option?
Process Data the partition followed by Process Index
Another way i found to resolve this issue is that for the changed records, I can do the update cube and update that particular leaf cell.
For the new records, I can do the Process Incremental.
Yep, I can vouche for the duplicating effect. I trouble shot an SSRS report for an hour before I figured out I had doubled my counts. Lesson Learned.
I will vouche for your last comment about duplicating records. It took me about an hour of trouble shooting my SSRS report to figure out I had duplicated records. Lesson learned.
Interesting and simple explanation of Process Incremental. Good information to know. Thanks